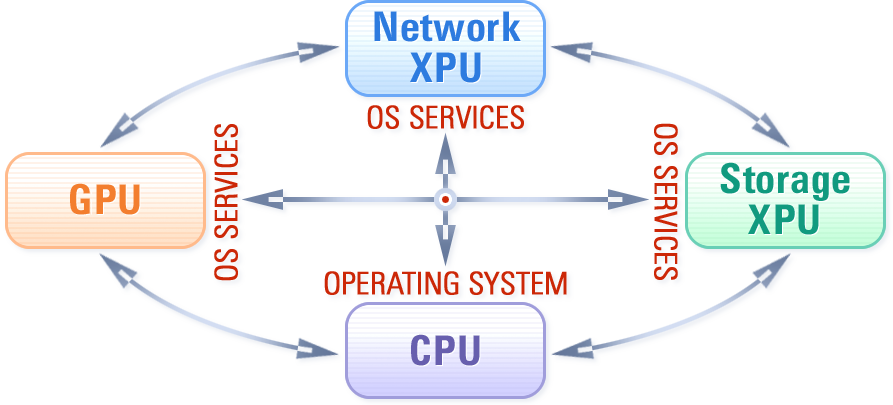
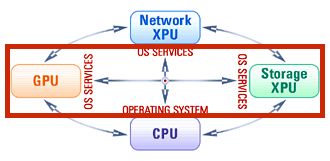
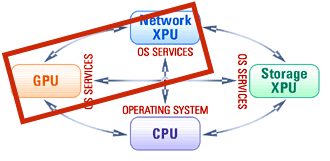
Specialized programmable hardware accelerators, i.e., GPUs, Smart Network Adapters, Smart Storage Drives and FPGAs, have become essential components of modern computing systems. However, such heterogeneity of processing elements challenges the software architecture dominated by traditional CPU-centric programming models and abstractions.
We are working on bridging the gap between modern hardware and software by introducing a new accelerator-centric operating system architecture. The goal is to turn the accelerators into first-class programmable devices on a par with the CPU, thereby hiding the hardware heterogeneity behind convenient OS abstractions. Many projects in the lab materialize this vision.
See the video with the overview here, and a more recent talk here.
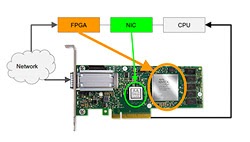 We develop novel OS abstractions and a framework for accelerating server applications on FPGA SmartNICs, as well as a novel FPGA-based driver for direct control of an ASIC NIC to make the NIC hardware offloads accessible to the FPGA logic
We develop novel OS abstractions and a framework for accelerating server applications on FPGA SmartNICs, as well as a novel FPGA-based driver for direct control of an ASIC NIC to make the NIC hardware offloads accessible to the FPGA logic
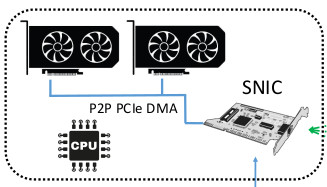 We show that SmartNICs today provide enough horse-power to drive up to hundred of low-latency ML accelerators, completely offloading network stack processing from the host CPU. When running an inference server with 12 GPUs at 300usec per inference request, the CPU utilization is 0.
We show that SmartNICs today provide enough horse-power to drive up to hundred of low-latency ML accelerators, completely offloading network stack processing from the host CPU. When running an inference server with 12 GPUs at 300usec per inference request, the CPU utilization is 0.
 This project shows how to enable native file access from the GPU kernel. We build a GPU file system layer (GPUfs), with GPU-centric memory-mapped file management (ActivePointers), GPU-page fault based memory mapped files integrated with the Linux page cache (GAIA) and full integration of peer-to-peer GPU-to-SSD transfers with the Linux page cache and file I/O API (SPIN).
This project shows how to enable native file access from the GPU kernel. We build a GPU file system layer (GPUfs), with GPU-centric memory-mapped file management (ActivePointers), GPU-page fault based memory mapped files integrated with the Linux page cache (GAIA) and full integration of peer-to-peer GPU-to-SSD transfers with the Linux page cache and file I/O API (SPIN).
 We develop convenient programming abstractions for GPUs to perform highly efficient low-latency network I/O without the use of CPUs. The GPU networking layer is used to design low-latency multi-GPU network servers that do not use the host CPU.
We develop convenient programming abstractions for GPUs to perform highly efficient low-latency network I/O without the use of CPUs. The GPU networking layer is used to design low-latency multi-GPU network servers that do not use the host CPU.
