GPUfs system enables direct access to a host file system from GPU kernels.
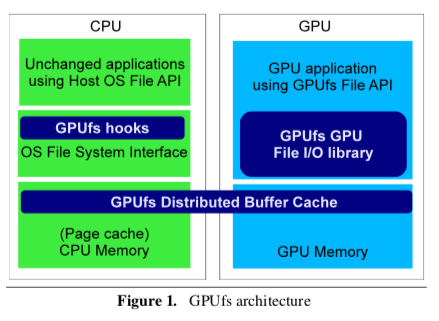
A preliminary prototype is available from GITHUB. It is being actively updated so please download the release tags.
The prototype is a work in progress, so at the moment it can be used only to illustrate the main concepts.
GPU Code sample
The following GPU kernel illustrates data processing directly from file. No CPU code development is necessary.__global__ void file_cpy_to_gpu(char* src_file){ int zfd=gopen(src,O_GRDONLY); int filesize=fstat(zfd); for(size_t me=0; me<ONE_BLOCK_READ; me+=FS_BLOCKSIZE) { int my_offset=blockIdx.x*ONE_BLOCK_READ; unsigned int toRead=min((unsigned int)FS_BLOCKSIZE,(unsigned int)(filesize-me-my_offset)); volatile void* data=gmmap(NULL, toRead, 0 , O_GRDONLY,zfd,my_offset+me); /** ...........................................................
process data from file
...........................................................
**/
gmunmap(data,0);
}
gclose(zfd);}
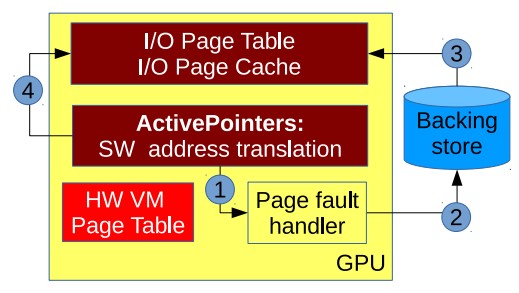
ActivePointers enable virtual address space management and page fault handling for GPUs.
Paper: “ActivePointers: A Case for Software Address Translation on GPUs”
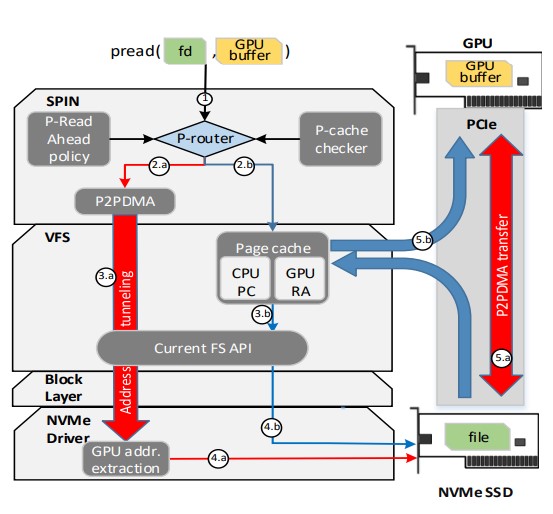
SPIN integrates Peer-to-Peer data transfers between GPUs and NVMe devices into the standard OS file I/O stack, dynamically activating P2P where appropriate, transparently to the user.
Paper: “SPIN: Seamless Operating System Integration of Peer-to-Peer DMA Between SSDs and GPUs”.
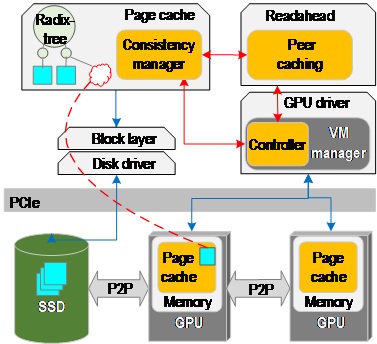 GAIA integrates GPU memory into the OS page cache and enables data-dependent GPU accesses to large files and efficient write-sharing between the CPU and GPUs.
GAIA integrates GPU memory into the OS page cache and enables data-dependent GPU accesses to large files and efficient write-sharing between the CPU and GPUs.
