 Proposed
Proposed
Recent theoretical work explores the idea of asymmetric cache blocking/tiling scheme for matrix multiplication scenarios in which the operand matrices have asymmetric element properties. Such scenarios can include mixed-precision matrix multiplication, or matrix multiplication between a data matrix and a random matrix (used in various randomized linear algebra and data sketching techniques). In this project, we would like to design, measure and evaluate matrix multiplication implementations on different platforms which will attempt to take advantage of these ideas. We will evaluate such matrix multiplications in CPU, GPUs, and TPUs using cloud platforms. For random matrices, we will evaluate whether different random distributions within the random matrices further affect the timing asymmetry of these multiplications. For mixed-precision multiplications, we will evaluate a spectrum of mixed-precision computations from low-precision (bf16) to high-precision (fp128, aka double double).
Prerequisites: Digital Systems and Computer Organization, Intro to Software Systems (or other prior knowledge in C/Cpp).

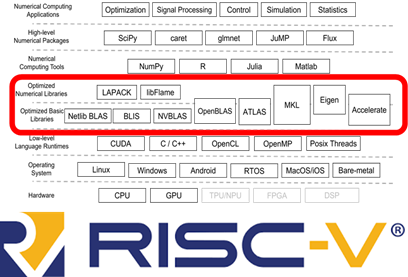
High performance numerical libraries lie at the base of many modern applications – machine learning, robotics, signal processing, simulation, data analytics and more. Most high-performance numerical libraries conform to binary interfaces and nomenclature set by the original BLAS and LAPACK projects. Commercial implementations such as Intel MKL, Apple Accelerate, and cuBLAS are often interchangeable thanks to this binary compatibility.
In this project, we will attempt to implement a high-performance BLAS implementation for the RISC-V vector extension, which can be integrated into a major open-source numerical library such BLIS, OpenBLAS or Atlas. A previous early implementation of high-performance matrix multiplication for the 0.7 draft specification of the RISC-V vector extension was implemented in the OpenBLAS project, but the RISC-V vector extension has changed since then. In contrast, in this project we are interested in the ratified version 1.0 RISC-V vector extension and extended scope of high-performance kernels.
In this project students will learn about the nuances of the RISC-V vector extension and variable-length vectors, as well as the principles of high-performance numerical computing kernels (cache blocking/tiling, software pipelining, etc.).
We will start with a functional implementation using a RISC-V ISA functional simulator supporting the vector extension, and then move to performance evaluation using more accurate timing models.
Prerequisites: Digital Systems and Computer Organization, Intro to Software Systems (or other prior knowledge in C/Cpp).
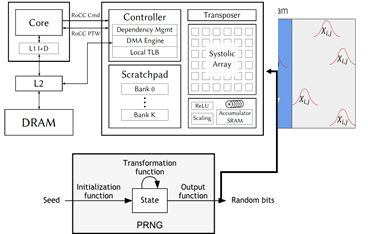
Recent research in computationally-efficient algorithms has explored the benefits of randomized linear algebra and probabilistic guarantees in data analysis and data processing. Techniques such as linear sketching for least squares problems and randomized low-rank approximation have been used in-practice and in-the-wild in popular machine learning libraries such as scikit-learn. Many of these techniques require multiplication by random matrices with certain properties. These matrices are often generated once and stored in memory for the remainder of computation. However, on-the-fly generation of these matrices has the potential to reduce memory bandwidth requirements, allowing for consistent matrix multiplication operation at the computational peak of a processor.
In this project, we will explore the design of a hardware reproducible random matrix generator based on PRNGs with programmable seeds, which can be integrated into hardware matrix-multiplication units. The purpose of the hardware unit will be to be able to support a software scheme in which a large random matrix is blocked/tiled into smaller matrices based on the processor cache size, and the blocks of the random matrix are regenerated/recomputed using PRNGSs using stored seeds. The hardware unit will be integrated into an open-source RISC-V platform for evaluation using custom instructions or memory-mapped IO. We will evaluate the area, power, and throughput of the hardware unit, and analyze whether it helps support more efficient randomized linear algebra compared to traditional vector and matrix multiplication hardware units.
Prerequisites: Prerequisites: Digital Systems and Computer Organization, Verilog/Lab1
One of the key differentiating properties in the recent proliferation of matrix-multiplication hardware acceleration is the use of low-precision and mixed-precision datatypes. Optimized deep learning workloads have been shown to be resilient to low-mixed-precision datatypes, which enable efficient hardware implementations of matrix-multiplication. Recent work (https://arxiv.org/pdf/2203.03341.pdf ) has demonstrated the ability to recover single-precision matrix multiplication accuracy using NVIDIA Tensor Core FP16 and TF32 datatypes. Single-precision matrix multiplication is often required for early accuracy evaluation of deep learning models as well as correct computation of scientific computing workloads and simulations.
In this project, we would like to evaluate this technique on additional cloud-based deep learning matrix multiplication units (with potentially different rounding modes) such as the TPU on Google Cloud Platform and Inferentia and Habana on Amazon Web Services. Based on the results of the evaluation, we will investigate whether different matrix units may require different error correction methods. We will also investigate whether potential use of stochastic rounding could theoretically (or in simulation) enable these low-precision matrix units to achieve even higher single-precision performance.
Prerequisites: Digital Systems and Computer Organization, Computer Architecture, Intro to Machine Learning

Several open-source SoC frameworks have been created in the academic community in recent years, including Chipyard, ESP, OpenPiton, Caravel, and BlackParrot. While these have simplified the design of custom open-source digital systems, their integration with custom analog mixed-signal circuit components is still a challenge. In this project, we would like to investigate a “generic” wrapper for the integration of an analog mixed-signal component with a digital open-source SoC framework. We will use the open-source Skywater 130nm PDK, select 2 open-source analog components out of the open-source projects submitted to the public Skywater 130nm shuttles, and attempt to integrate them using a single wrapper interface within the Chipyard system. This is an open-ended question, and requires the investigation of multiple types of analog mixed-signal blocks (PLLs, SerDes, ADCs), meta-programming and code-templating, and understanding of generator-based SoC design frameworks.
Prerequisites: Digital Systems and Computer Organization, Intro to VLSI, Electronic Circuits
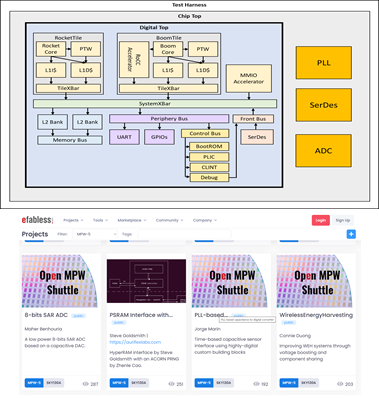
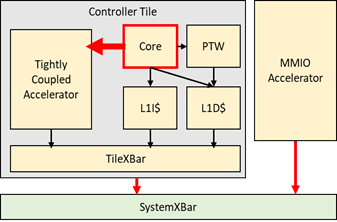
A key property for accelerator controllers is instruction and task descriptor issue bandwidth. Firmware for most accelerator controllers is often fairly predictable without many branches (often loops, but not complex control flow).
We would like to evaluate the open-source RISC-V processor ecosystem for processors which are most suitable to become accelerator controllers.
We will define a small benchmark suit of code sequences representing typical accelerator configuration and offload execution flows for a range of accelerator programming methods such as task descriptors for MMIO accelerators and instruction sequences for extensible cores with custom instructions. We will then evaluate the available RISC-V processors using either high-level instruction-count-based simulation or cycle-accurate simulation.
The goal of the project will be to create a taxonomy of processors for their suitability to different types of accelerator complexity based on accelerator input and configuration properties.
Prerequisites: Digital Systems and Computer Organization, Computer Architecture
Deep learning models have shown the ability to capture information about many patterns, including language patterns, code patterns and modulation patterns. In this project we will investigate usages of deep learning models within the context of computer networking protocols. We would like to evaluate whether deep learning models can be trained to identify and parse multiple layers of network protocols out of a stream of bits. We will evaluate multiple training and fine-tuning approaches such as token classification into fields and masked-field training.
We would also like to evaluate whether similar generative models could be able to generate sequences of packets of realistic network protocol scenarios, to be used to test drivers for network protocol IP.
Finally, we would also like to evaluate whether the values of fields of an internal header within a packet can be predicted based on the values of the most external headers of the packets and additional features such as the history and pattern of packet arrivals. This prediction ability may help enable speculative execution within offload NIC stack).
Prerequisites: Digital Systems and Computer Organization, Computer Networks, Intro to Machine Learning
Stochastic rounding has emerged as a popular method to improve the accuracy of floating point computation, particularly with low-precision and mixed-precision machine learning workloads. In this project we would like to evaluate whether stochastic rounding has different rates of accuracy maintenance for different DNN operators. In particular, we would like to evaluate different mixes of convolutions, transformers, fully connected layers and normalization functions.
We will start by constructing a stochastic rounding evaluation platform in simulation (due to the current low availability of stochastic rounding hardware). We will then generate a range of DNN models out of a common set of DNN operators of different sizes (similar to NAS process), and evaluate their inference accuracy using low-precision datatypes compared to single-precision results and compared to alternative rounding modes
Prerequisites: Digital Systems and Computer Organization, Intro to Machine Learning
Some additional background information: https://arxiv.org/pdf/2001.01501.pdf
The open-source silicon ecosystem has grown rapidly since the popularization of the RISC-V ISA. While there is an availability of multiple open-source RISC-V cores within the ecosystem, replacing an existing controller core within an embedded project may still be challenging due to bus and communication ecosystems that are often packaged together with controller cores. Such examples include Avalon with Intel NIOS cores, AXI with ARM cores, and TileLink with SiFive cores. While certain bus protocol converters can be occasionally found (for example, Tilelink converters exist within the Rocketchip ecosystem), we would like to create an open-source Verilog-based conversion library between bus protocols, that can also be verified using verification-IP (VIP). In this project, we will start the development of such a library, and evaluate it by finding an open-source RISC-V core and replacing the busses from TileLink/AXI to Avalone, Open-Core Protocol (OCP) and/or the Wishbone bus protocol.
Prerequisites: Digital Systems and Computer Organization, Computer Architecture
Project definition:
In this project, the students will port one of the lab’s novel algorithms to an ARM processor while focusing on efficiency and performance. To do so, the students will need to check ARM’s various components, such as its SIMD engine, L1/2/3 cache latency, and multi-core synchronization. The project will give the student hands-on on C/C++ languages.
Project requirement:
Mamat/Matam + Intro to Operating Systems courses
Motivation:
Using co-processors for offloading tasks is a leading directive in data-center giants: instead of wasting expensive Intel CPU time, use cheap co-processors (e.g., ARM, RISC-V, etc.). While the most efficient way for sending/receiving data from/to the CPU is via PCIe (512 Gb/s), there are many cheap solutions (Raspberry PI for example) that offer relatively powerful ARM cores with USB3.0 connectivity (5Gb/s). Using these might be a good trade-off for compute-intensive tasks that do not require much data transfer between the devices. The project will give the student hands-on on C/C++ languages.
Project definition:
In this project, the students will:
(1) Write a Linux module that accepts function calls from the user space and sends them efficiently to a Raspberry-PI device using a USB3.0 connection. This will require developing an API and a communication protocol between the host and the device.
(2) Benchmark the connectivity performance between the host and the R-PI device in terms of throughput and latency.
Background requirements:
(1) Mamat/Matam + Into to Operating Systems courses
(2) Lab on operating systems – bonus, not mandatory
(3) Accelerated systems course – bonus, not mandatory

This project focuses on the problem of automatically detecting new speculative execution vulnerabilities on modern CPUs. These vulnerabilities, such as Spectre, Meltdown and Foreshadow, undermine the security of all existing CPU architectures, but their detection is manual and thus hard.
Our tool, Revizor [https://github.com/hw-sw-

A computer network is a set of computers linked together using network switches.
To communicate, computers send network packets to each other using some communication protocol.
These packets traverse the network, passing through a few network switches until they are received at the destination.
Traditionally, network switches are simple devices whose main functionality is receiving a packet on one port and forwarding it to another.
Recently, programmable network switches (e.g. Intel Tofino (https://www.youtube.com/watch?v=KKkUS9HI7I8)) have emerged.
The packet processing logic of these switches is programmable using domain-specific languages like P4 (https://www.youtube.com/watch?v=qxT7DKOIk7Q&list=PLf7HGRMAlJBzGC58GcYpimyIs7D0nuSoo&index=2).
This programmability has enabled a host of new applications, beyond simple packet forwarding.
To get started with P4 programming, the developers of the language created a set of exercises that anyone can download and experiment with. (https://github.com/p4lang/tutorials)
One of these exercises is a P4 calculator. (https://github.com/p4lang/tutorials/tree/master/exercises/calc)
In this exercise, the switch is programmed in P4 to work as a simple calculator.
It receives packets with a custom header that contains two integer operands and an operation (e.g. addition, multiplication, …).
The switch parses this header, applies the operation on the two operands, writes the result back into the header and returns the packet to the sender.
The project is to extend this calculator design into general computation, like a simple CPU.
The basic idea is to have a custom header which contains a few registers, like the operands of the calculator.
Instead of the operation, the header will also contain a few lines of “code”.
This code will be similar to basic assembly instructions, e.g. ADD, SUB, LD/ST, MOV and JMP.
In this system, the calculator example can be implemented with a single instruction, e.g. “ADD R1, R2, R3”.
This system would also allow storing values on the switch itself (using Load/Store instructions).
Therefore, packets can write values into the switch which can be read by later packets.
General computation on a programmable switch can be useful for two reasons: high connectivity and fast packet processing.
As a simple application of this system, consider a few servers connected to a common switch.
Suppose these servers would like to calculate a histogram of the characters in a large body of text.
This text can be divided over the servers, and 128 counters (one for each ASCII value) will be initialized to zero on the switch.
Each server will then calculate a histogram on its own portion of the text, and then use the custom packets to add its own histogram to the global one in the switch.
When all servers finish, each of them can read the histogram of the whole text from the switch.
In the project you will:
1. Learn the basics of the P4 language using the P4 tutorial exercises.
3. Define a specification for the new custom header and the supported instructions.
4. Implement the P4 program that parses this header and executes the instructions.
5. Simulate the switch using the behavioral model (used in P4 tutorial).
a. Run basic packets to test the functionality.
b. Implement the histogram example and simulate it.
c. Implement two other applications that utilize this new functionality and can benefit from running in a switch.
6. Write a project report.
Requirements:
– Programming in Python/C/C++
– Basic networking course
– Basic computer structure course (registers, assembly, …)
Recent advances in networking research have paved the path for highly performant network processors. The status quo of programmability equals low performance does not hold anymore.
Programmable data-plane switches, e.g. Intel Tofino, offer the same performance as fixed-function switches while providing data-plane programmability at the same cost.
Many previous projects have shown the performance benefits of in-switch acceleration, such as load balancers, network monitoring, and DDoS detectors. These applications maintain persistent state. Stateful objects such as registers, counters, and meters, exposed by the P4 language, are updated purely by the data-plane and persist across multiple packets. Effectively, allowing a packet to update the state, and the next one to read it, all at line-rate speed. Two common properties to all these projects: first, they are stateful. Second, they are designed for a single switch. However, distributed state management in the data plane is a challenging problem due to the strict limitations of the hardware.
We have built a few replication protocols aiming to facilitate the design of distributed stateful data-plane applications while providing well-defined consistency guarantees. We encourage you to read our paper for more details.
The goal of the project is to showcase these protocols by implementing distributed stateful sketch-based applications entirely in the data plane.
In this project, you will complete the P4 tutorials to learn the basics of the P4 behavioral model (simulator). You will then implement a data-sketch, e.g. quantile sketch, UnivMon. Then, you will learn the Tofino extensions. And, finally, you will implement and evaluate a distributed design on the real hardware.
We are also looking for excellent UG students and graduate students for more research-oriented directions, here we will design and optimize the core of the protocols:
Designing data-plane recovery protocols.
Optimizing inter-switch communication, e.g. selective updates and header minimization.
We are also open to hearing your ideas too! Do you have a different project in mind? Great! Reach out and we will discuss the details.
Expected duration: 1-2 semesters depending on the track.
Mandatory prerequisites:
C/C++ programming skills
A basic course in networking

