Range matching is a crucial component in computer systems and is used extensively in virtual memory, network switches, storage devices, and more. The term range matching refers to the process of locating a single pair out of a set of range-value pairs; given a numerical input, the matching algorithm finds a range that contains the input number and returns the value that corresponds to that range. This process gets complicated in the presence of multidimensional ranges, as in the case of packet classifiers in network routers and firewalls. In these systems, the lookup process must be completed in the order of nanoseconds for meeting performance requirements. Since the memory latency is orders of magnitude slower than that of the CPU, modern algorithms for multidimensional range matching strive to reduce the number of memory accesses they require. Unfortunately, existing methods fail to scale to the number of ranges and spill out of the CPU core cache (L1, L2 caches) when their number of ranges is high, resulting in compromised system performance.
In our work, we take the ideas of learned indices [1] and apply them to multidimensional range matching. We introduce the Range Query Recursive Model Index (RQ-RMI) and show that it can learn the distribution of non-overlapping range-value pairs while fitting into the CPU L1 cache. It does that by approximating the pairs function representation, defined as a mapping from a range to its position within a table. With sorted non-overlapping ranges, this function is monotonic and can be estimated by the model. The RQ-RMI training technique guarantees a tight upper bound on the approximation error for the entire input domain; thus, the lookup process finds the correct pair by scanning the table within the estimation error proximity (see Figure 1). In the multidimensional case, we use a suboptimal algorithm for partitioning the multidimensional ranges into subsets that do not overlap on a single dimension, called Independent Sets (iSets). Then, we use an RQ-RMI model per iSet for finding a match. Since it is inefficient to use a model for a small number of ranges, we combine small iSets into a remainder set and use other existing techniques for matching its ranges. We select the highest priority results out of all subsets.
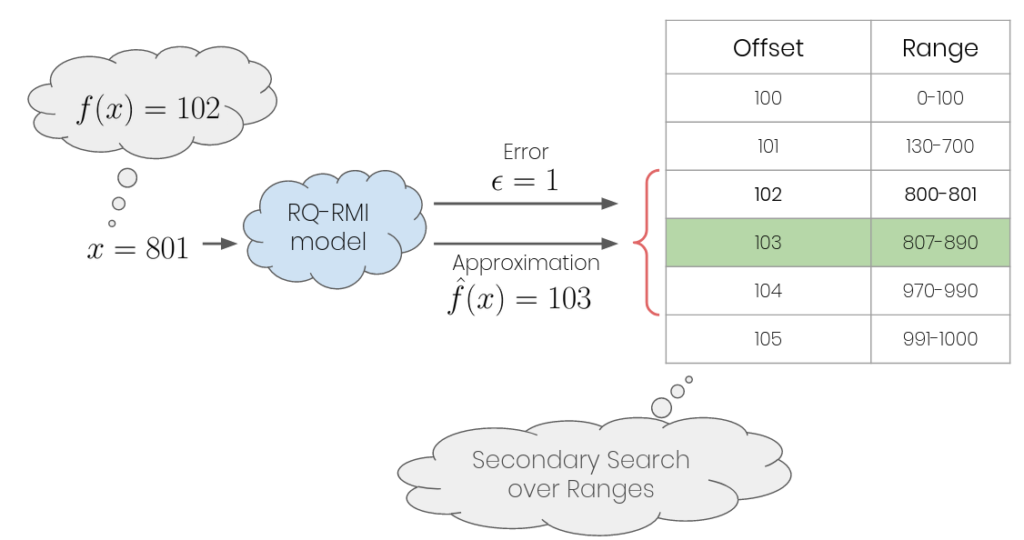
Figure1: RQ-RMI lookup process
Our method, called NuevoMatch [2], acts as an accelerator for existing algorithms in the field of multidimensional range matching; it uses iSets and RQ-RMI models for handling most of the ranges while leaving a small remainder to be managed by the original algorithm. NuevoMatch offers a new point in the design space of range matching algorithms, replacing pointer chasing (the primary method used today) with neural network inference. This solution is promising given the poor scalability of on-chip memories and the development of computational engines in modern and emerging CPUs.
NuevoMatch allows performing packet classification with an impressive speedup compared to other state-of-the-art techniques. It compresses the memory footprint required for indexing range-value pairs by up to 80x (Figure 2), achieving throughput speedups up to 2.5x (Figure 3). As part of our ongoing work, we use NuevoMatch to replace the matching algorithm in Open vSwitch [3], one of the most popular software switches used by cloud providers. Our experiments with real-world traffic traces and between 1K to 500K classification rules demonstrate up to 24x speedups while supporting 60K rule updates/second, by far exceeding the original OVS.
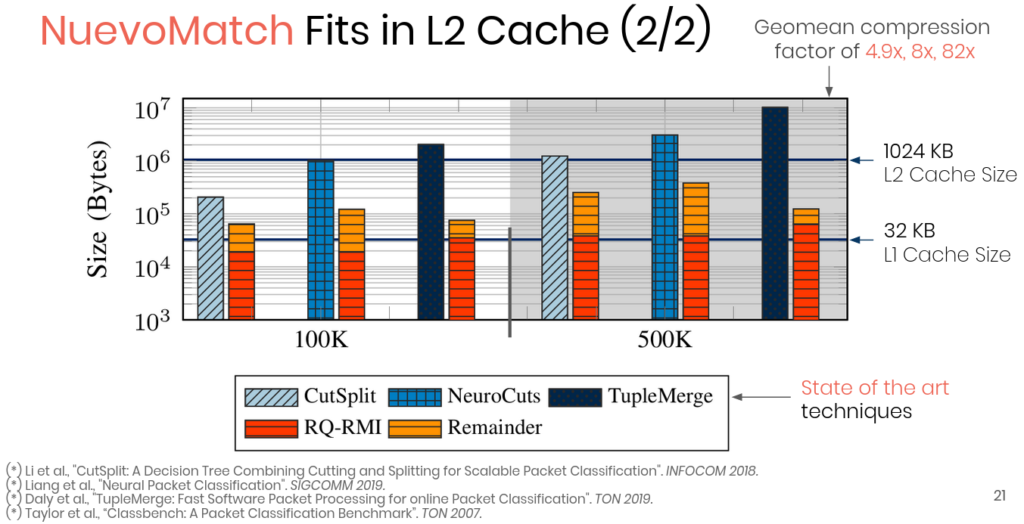
Figure 2: NuevoMatch compression factor compared to state-of-the-art
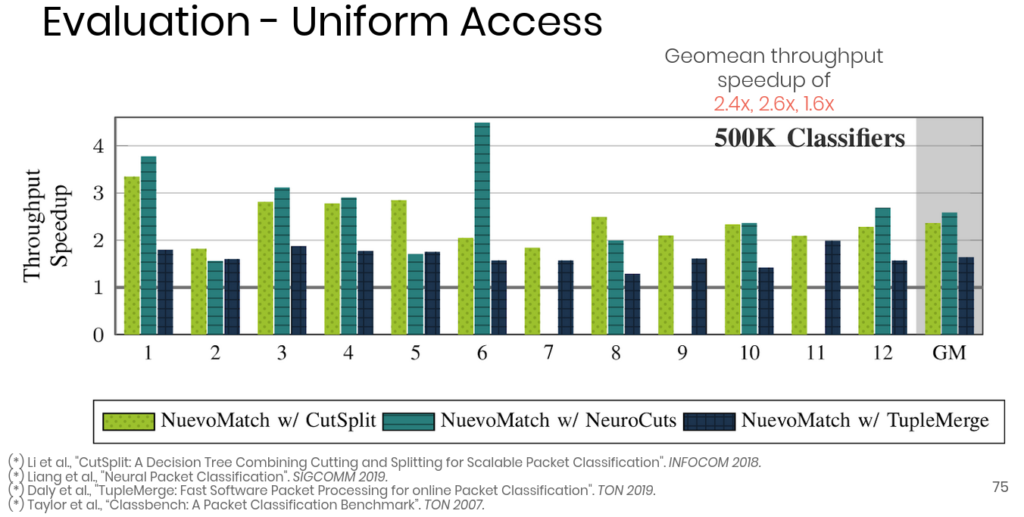
Figure3: NuevoMatch speedup comapred to state-of-the-art
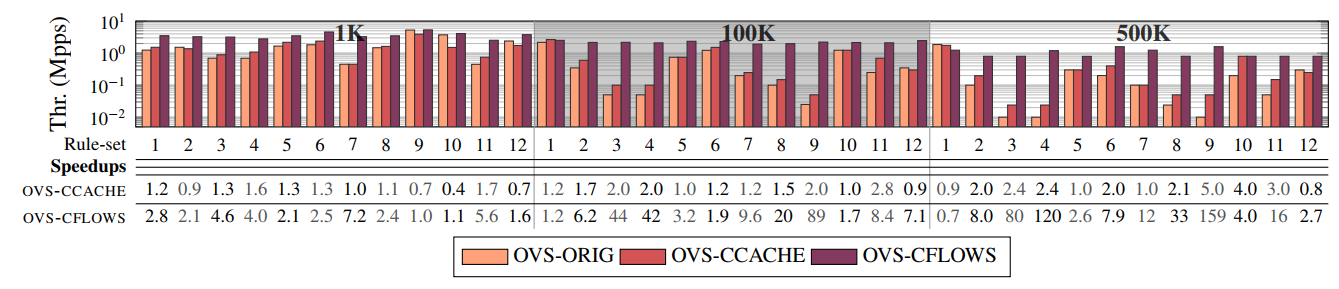
Figure4: Speedup achieved by using NuevoMatch in Open vSwitch for 1K, 100K, and 500K OpenFlow rules. Legend: OVS-ORIG – unmodified Open vSwitch (OVS). OVS-CCACHE – mildly modified OVS with NuevoMatch as part of its data-path. OVS-CFLOWS – highly modified OVS with NuevoMatch replacing its datapath.
[1] The Case for Learned Index Structures (SIGMOD, 2018)
[2] A Computational Approach to Packet Classification (ACM SGICOMM, 2020; Source Code, Paper, Slides, Videos)
[3] Scaling Open vSwitch with a Computational Cache (USENIX NSDI, 2022; Paper and Slides)
