Intel SGX allows creating enclaves with practical extensions to the x86 architecture. Effectively, in SGX, the operating system (OS) is responsible for managing enclaves virtual-to-physical memory mappings through modifications to the page table.
Previous works have shown this enables an OS-level attacker to induce spurious page faults and through this page fault side-channel, recover secret information processed in the enclaves. Effectively, the attacker may unmap pages and learn when the enclave attempts to access data on these pages by observing page faults for these faulted addresses. Alternatively, the attacker can clear the accessed or dirty bits for these pages and learn enclave accesses to them by observing changes to these bits’ values.
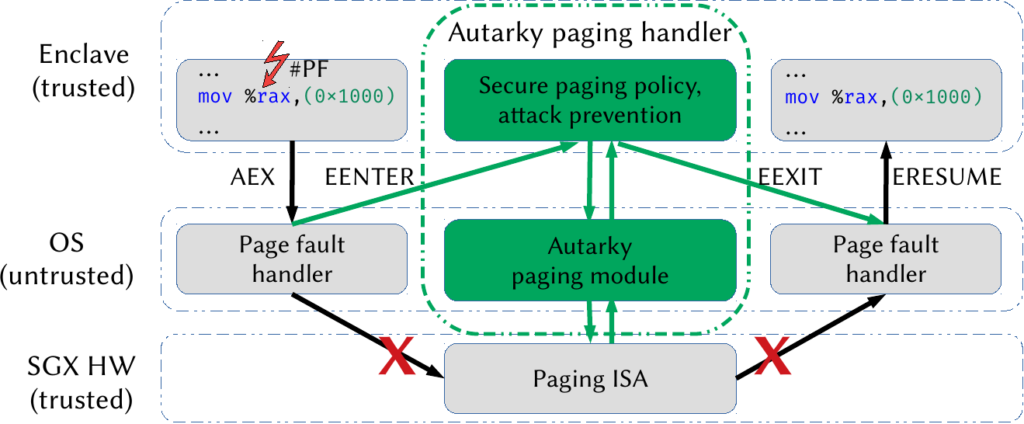 We propose a pragmatic solution that is compatible with the existing SGX design with Autarky. Autarky revokes from the OS control of EPC paging policy and delegates it to a trusted self-paging runtime.
We propose a pragmatic solution that is compatible with the existing SGX design with Autarky. Autarky revokes from the OS control of EPC paging policy and delegates it to a trusted self-paging runtime.
With Autarky, the trusted processor enforces the invocation of the trusted page fault handler and hides enclave page fault information and access/dirty bits from the OS. Effectively, Autarky establishes a cooperative mechanism between the OS and an enclave runtime. The trusted page fault handler tracks expected page mappings and can, therefore, detect spurious unexpected page faults and apply a defense mechanism to avoid leaking sensitive information to the attacker. Note, Autarky takes a similar approach to SGX protection against spurious mapping attacks, but instead, Autarky removes the control from the page fault side-channel.
Using Autarky, the trusted page fault handler is responsible for self-paging and can control the leakage due to legitimate page faults. For example, for enclaves with a working set that exceeds their available physical memory. We present three such policies next.
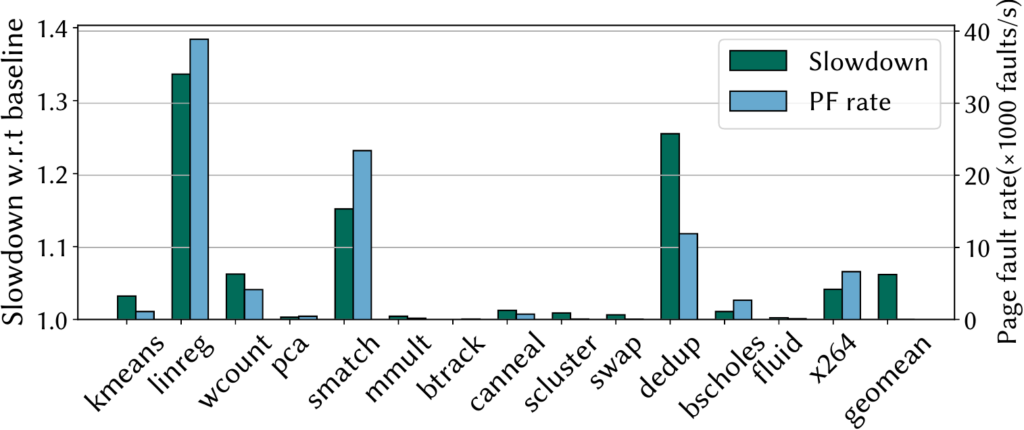 Similar to previous works that proposed limiting the number of exceptions to detect the page fault side-channel attack, we apply this heuristic as a bounded-leakage demand-paging policy. However, with Autarky we can put a limit only on page faults instead of any type of exception, we do not need any modifications to the applications, so we may support legacy binaries and we only need to apply this limit for legitimate page faults.
Similar to previous works that proposed limiting the number of exceptions to detect the page fault side-channel attack, we apply this heuristic as a bounded-leakage demand-paging policy. However, with Autarky we can put a limit only on page faults instead of any type of exception, we do not need any modifications to the applications, so we may support legacy binaries and we only need to apply this limit for legitimate page faults.
We evaluate this policy on the Phoenix and PARSEC benchmark suites. It requires no application modifications and results in a 6% geometric mean slowdown compared to an insecure baseline. In our paper, we propose further optimizations to further reduce this slowdown to 2%.
ORAM is a well-established cryptographic primitive that provably obfuscates memory accesses by dynamically re-encrypting and re-shuffling memory contents. To support oblivious paging we develop on our early work on Secure Virtual Memory. We recompile enclaves with CoSMIX and an ORAM memory store that supports the caching of pages in the trusted enclave memory. The latter is possible since Autarky prevents spurious page faults to occur for trusted enclave memory. We observe a significant improvement in performance since we only have to invoke the costly ORAM algorithm for page fetches and evictions.
ORAM obfuscates accesses to all enclave pages. However, not all applications require such a strong guarantee. For example, for data structures such as a hash table, it may be necessary to hide which hash bucket was accessed, but not whether the table was accessed at all. We propose a new abstraction called page clusters to allow developers to express such requirements either manually or automatically.

A page cluster is a consistent set of enclave-managed pages that are evicted and fetched together. Whenever a fault occurs, the system deterministically fetches and maps all the other pages in a cluster together with the faulting page. Thus, the attacker cannot differentiate which of the fetched pages caused the fault, even if the same fault occurs many times. We note that clusters differ from large pages, since they need not be physically or virtually contiguous, and can be assembled or broken down dynamically.
Note, page clusters are especially useful for protecting code pages. For example, having all pages of a library be part of a cluster would only reveal to an attacker that the library was accessed but not which internal branch was taken or even which function was executed.
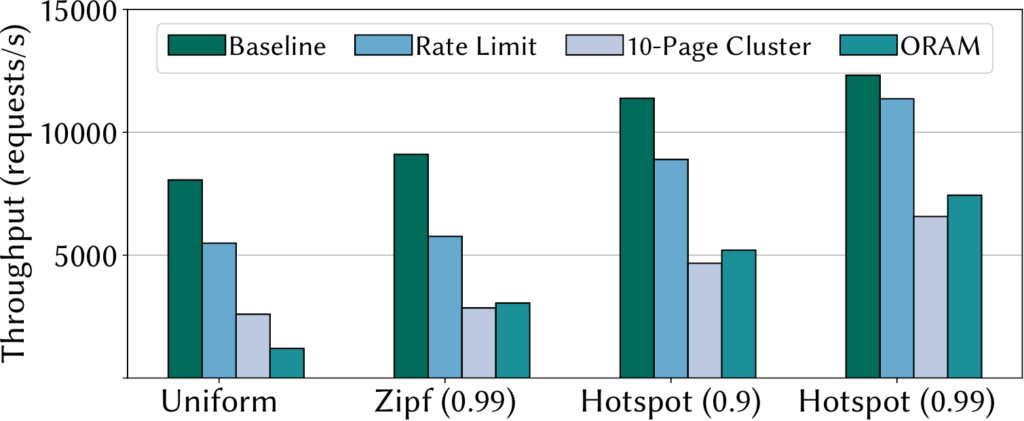 Finally, we used the Memcached key-value store to evaluate the performance impact of the different secure paging policies. To that end, we pre-loaded Memcached with more than 2x the available enclave memory to force legitimate page faults and issued random 1KB GET requests with different skewness rates. When there are more hot requests there is a bigger chance of caching and avoiding page faults. We configure the rate-limiting policy with an infinite limit and ORAM and page clusters to cover the entire key-value store. The latter adds items to a cluster until it fills 10 pages, then a new cluster is formed. The different policies provide a tradeoff between performance and security guarantees and can be chosen by developers depending on the use case. For example, with the hottest request distribution, ORAM is only 60% slower than the insecure baseline.
Finally, we used the Memcached key-value store to evaluate the performance impact of the different secure paging policies. To that end, we pre-loaded Memcached with more than 2x the available enclave memory to force legitimate page faults and issued random 1KB GET requests with different skewness rates. When there are more hot requests there is a bigger chance of caching and avoiding page faults. We configure the rate-limiting policy with an infinite limit and ORAM and page clusters to cover the entire key-value store. The latter adds items to a cluster until it fills 10 pages, then a new cluster is formed. The different policies provide a tradeoff between performance and security guarantees and can be chosen by developers depending on the use case. For example, with the hottest request distribution, ORAM is only 60% slower than the insecure baseline.
This project was performed in collaboration with Andrew Baumann (Microsoft Research)
