This work focuses on how to build a fast and efficient accelerated network server for data centers, in order to enable direct networking from the accelerators in the system by offloading the data and control planes onto a SmartNIC.
Recently, there is a trend where more and more AI applications are being used. As a response, major cloud providers have already deployed many accelerators in their data centers, e.g. FPGAs in Microsoft Azure, GPUs are used in the Elastic Inference in Amazon clouds, TPUs in Google AutoML, and more.
If you look on these servers’ architecture, you will find out that they all are using the traditional host-centric architecture, where the CPU manages all the peripheral devices in the system, especially the accelerators. As an example, in the NVIDIA DGX-1 server, which is the first server used for AI purpose, there are 8 Tesla GPU cards, but in order to drive these accelerators they use 40 CPU Xeon cores.
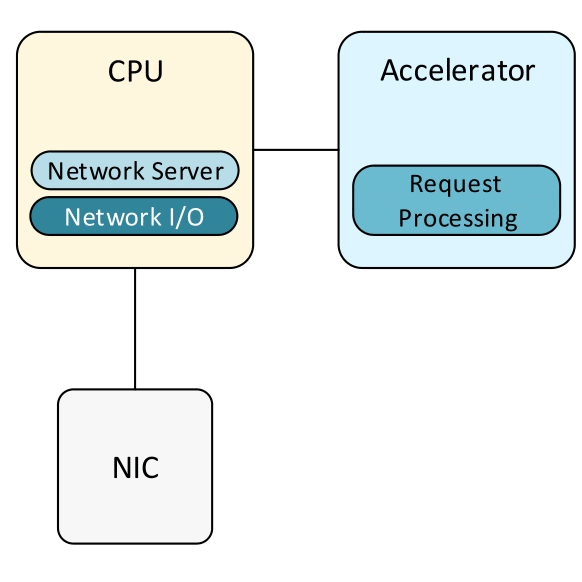
The CPU in these servers are used for 2 purposes; managing the accelerators and network I/O tasks, which are inherently I/O- and control-bound. As a result, using Xeon cores for such tasks is definitely possible, but also wasteful. These tasks don’t require the full power of super scalar, out of order X86 CPU architecture to achieve high performance. Instead, we can exploit these cores by running a latency-sensitive workloads, such as memcached.
Programable peripheral devices, such as SmartNICs are becoming widely used in research, and also in industry. Therefore, our hypothesis is to use the SmartNIC as an accelerator manager in the system, and to free the CPU to run more suitable tasks. In this work, instead of using the traditional host-centric architecture, we use the accelerator-centric architecture in order to bypass the CPU when the accelerator needs to receive and send data to the network.
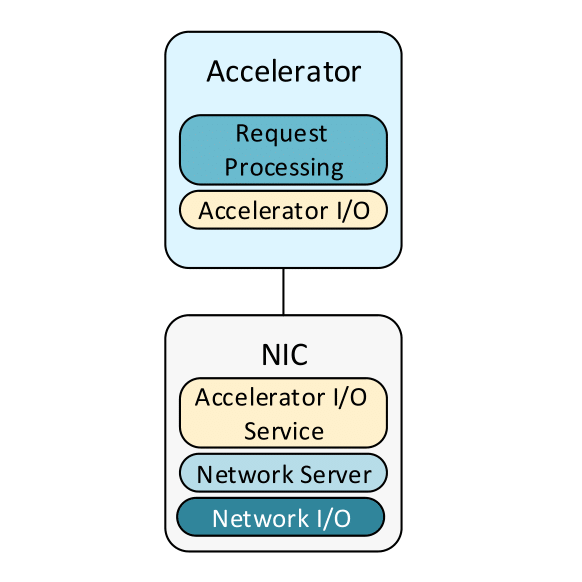
In this work, we are using the integrated RDMA accelerator in the SmartNIC in order to create one-sided RDMA channels between the accelerators and the SmartNIC. And by doing that, we can create a request-response queues in the accelerator memory, manage them on the SmartNIC, and allow them to send and receive data from the network.
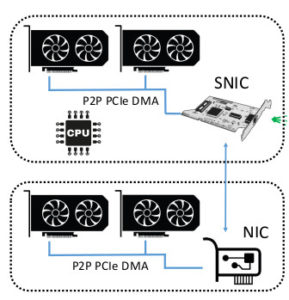
Lynx doesn’t require installing the accelerator’s driver on the SmartNIC, therefore it is portable for all accelerators that have the ability to expose their memory over PCIe. Also, Lynx supports UDP and TCP transport protocols, which are important in order to be able to integrate Lynx in the clouds, where most of the workloads are using UDP and TCP. Thanks for using RDMA internally – between the SmartNIC and the accelerator – Lynx is also scalable and can access remote accelerators that reside on a remote physical machines.
Lynx was implemented on the Mellanox Bluefield which is an ARM-based SmatrNIC. In addition, a partial implementation on Mellanox Innova, an FPGA-based SmartNIC. We used 2 different types of accelerators; NVIDIA GPUs and the Intel Visual Computer Accelerator (VCA).
Integrating new accelerators with Lynx is very simple, all what we need to do is to implement a light-weight library on the accelerator side in order to manage the message queues in the accelerator memory.
LeNet is a DNN used for recognition hand-written digits. LeNet was developed using TensorFlow, optimized by using the state-of-the-art TVM compiler for neural networks. LeNet runs only on the GPU without any code running on the CPU (neither on the SmartNIC).
For LeNet, using Lynx on BlueField outperforms the host-centric architecture. Lynx achieves 25% more throughput (almost achieving the max theoretical throughput) and 20% less latency comparing to the host-centric architecture. All this while using ARM cores (on the smartNIC). When running Lynx on Xeon core, for comparison purpose, we saw that Lynx on BlueField can achieve the same throughput with a negligible latency overhead when comparing to running Lynx on Xeon core.
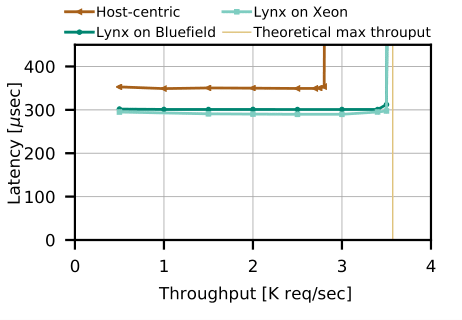
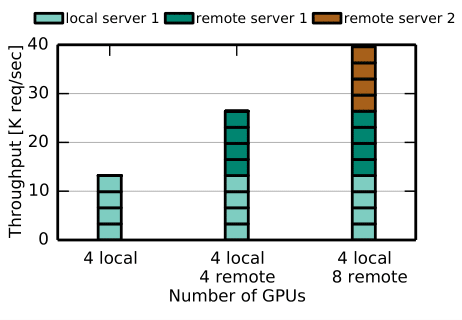
For compute bound applications, Lynx can scale linearly, until reaching the network processing bottleneck. And this is true for both local and remote accelerators.
Recently, in the GTC 2020 conference, NVIDIA has announced the new DPU (Data Processing Unit). A DPU is a system on a chip, or SOC, that combines an industry standard, high-performance, software programmable, multi-core CPU, typically based on the widely-used Arm architecture, tightly coupled to the other SOC components.
Quoting from NVIDIA blog: “The CPU is for general purpose computing, the GPU is for accelerated computing and the DPU, which moves data around the data center, does data processing.” – And this is exactly the idea behind Lynx, isn’t it?
Paper: Lynx: a SmartNIC-driven accelerator-centric architecture for network servers
