ActivePointers enable virtual address space management and page fault handling for GPUs. In particular, ActivePointers enable to mmap files into the GPU’s virtual address space, which allow to significantly simplify application development on GPUs, as mmap eliminates buffer allocation, read/write system calls, and file pointer arithmetics, as well as enable seamless serialization/deserialization of in-memory data structures to/from files.
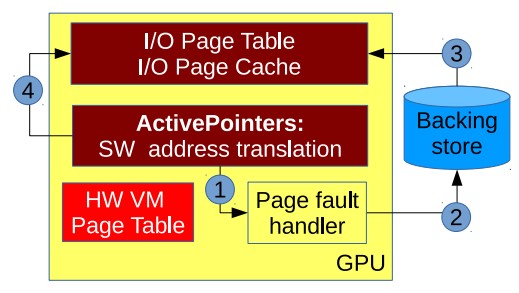
This work introduces a GPU-centric application-level VM management design. Since GPU VM manipulation is highly restricted, ActivePointers aims to overcome the limitations of the GPU’s hardware VM entirely in software.
In the GPU-centric VM management design using ActivePointers, the address translation layer triggers a page fault which is executed on the GPU itself (rather than on the CPU in a CPU-centric VM management design). Data is copied from the backing store and written into the GPU I/O page cache. The GPU updates the I/O page table. No accesses to the hardware VM page table are necessary.
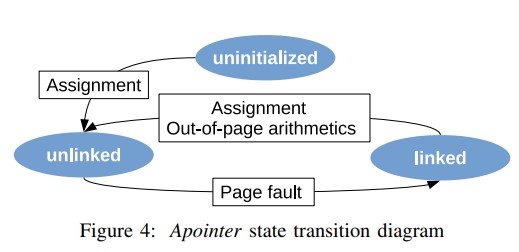
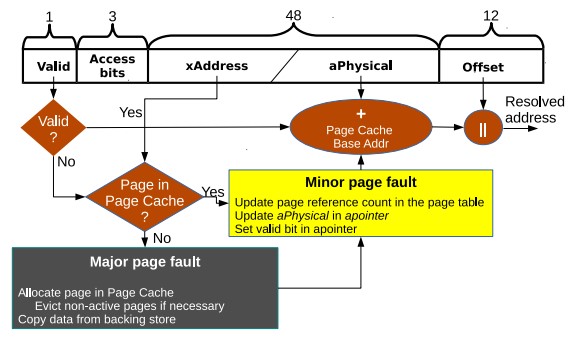
An apointer is implemented as a C++ class. It comprises two parts; a translation field, which stores the avirtual-to aphysical mapping and is hence used in every access to an apointer, and metadata fields, used only in page faults. The translation field is specifically designed to fit into 64 bit. This allows the compiler to cache it in a hardware register, which is crucial for reducing the overhead of fault-free accesses.
Address translation requests are aggregated, and our mechanism enables efficient access to an apointer in page-fault free and page fault cases. If no page fault are encountered by any of the threads, they quickly return the data without divergence. Otherwise, subgroups of threads accessing the same page select one thread from the group as a leader, which handles the page fault for that group.
We also implement a direct mapped TLB for simplicity. The TLB is implemented as a simple concurrent hash table in the per-threadblock scratchpad memory, enabling lock free search and locked modifications.
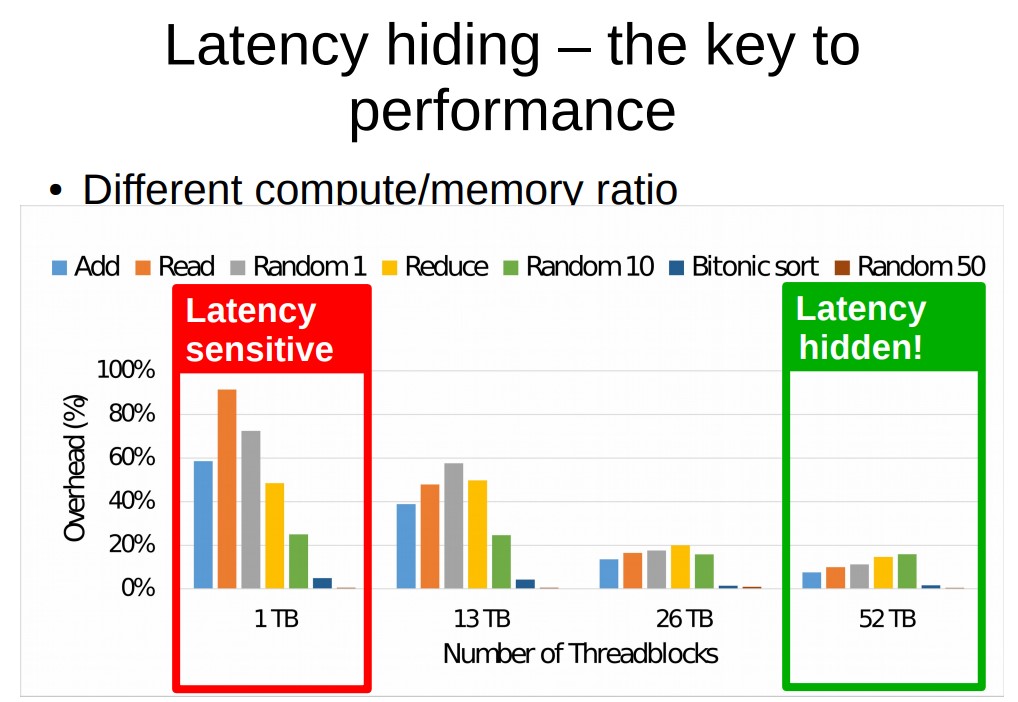
While the apointer dereferencing and arithmetics operations add computations on each access, their overheads become largely hidden as the GPU occupancy grows. This latency hiding ability of the GPU architecture is the key to providing efficient address translation in software.
An end-to-end image collage application (which substitutes blocks in the input image with “similar” images from a large dataset, where the similarity is defined as the Euclidean distance between image evaluation), ActivePointers does not exhibit any measurable overheads over GPUfs, while enabling convenient mmap operations to map the whole image dataset into the GPU memory.

