SPIN integrates Peer-to-Peer data transfers between GPUs and NVMe devices into the standard OS file I/O stack, dynamically activating P2P where appropriate, transparently to the user. It combines P2P with page cache accesses, re-enables read-ahead for sequential reads, all while maintaining standard POSIX FS consistency, portability across GPUs and SSDs, and compatibility with virtual block devices such as software RAID.
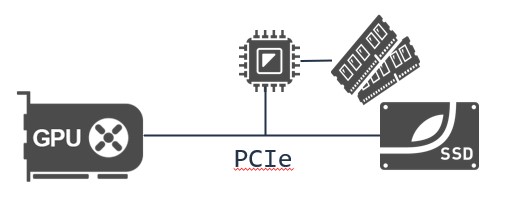
GPU vendors enable the use of P2P in order to transfer data from a DMA capable device straight to the GPU’s internal memory. SPIN enables data transfer between an SSD and a GPU only via PCI express, with no intermediate stop in system memory. This in by itself does not solve a myriad of performance limiting issues, such as data reads which can be served from a cached copy in the RAM.
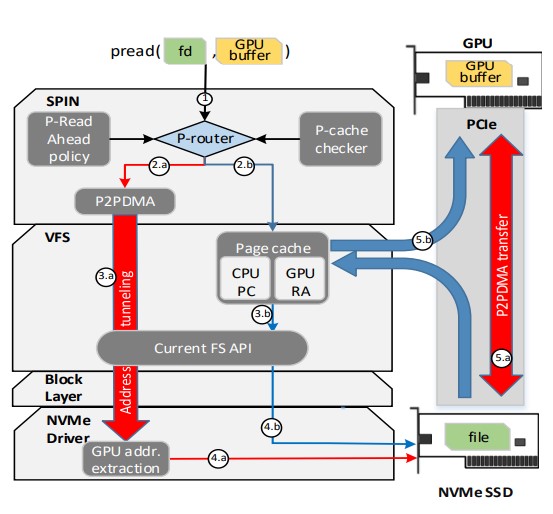
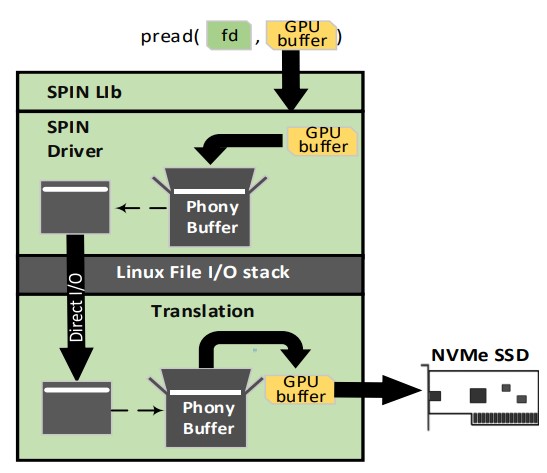
SPIN utilizes an address tunneling mechanism to enable P2P data transfers without tainting the Linux kernel. The main obstacle in achieving this is the lack of struct pages which describe the GPU memory, and thus does not allow a direct transfer from the SSD to the GPU. The address tunneling mechanism circumvents that by utilizing special phony buffers to envelope GPU buffer addresses.
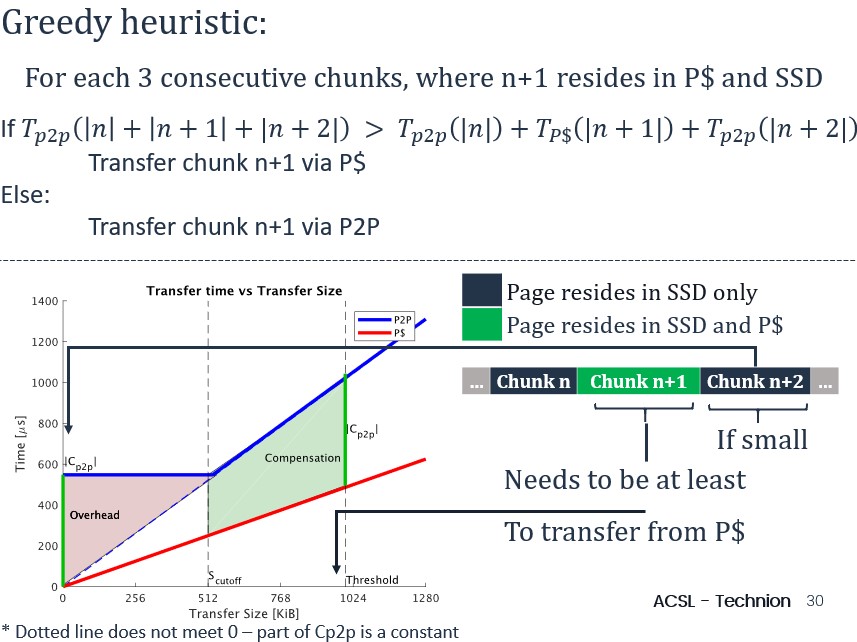
SPIN decides whether to transfer SSD data that partially resides in the page cache based on a greedy heuristic that approximates the overall data transfer time (via modeling SSD data transfer latency as a piece-wise linear function and performing parameter fitting).
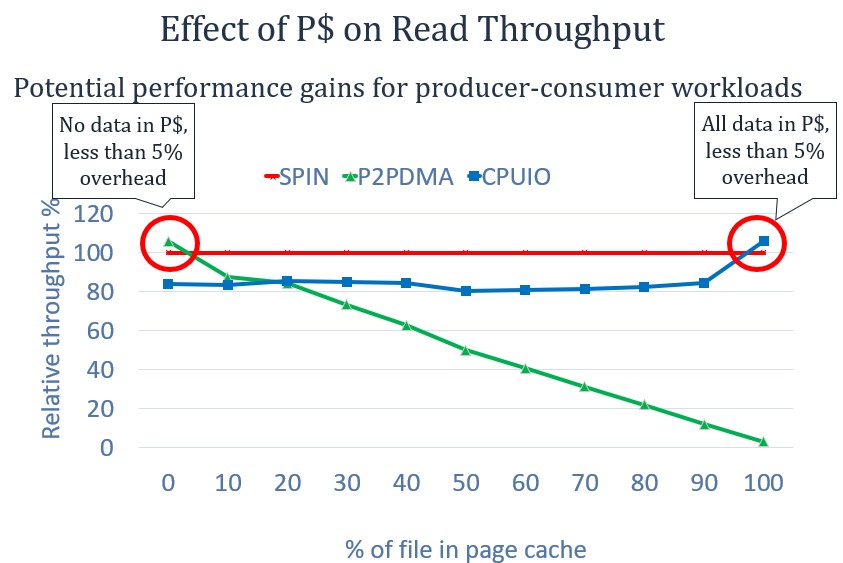
SPIN outperforms sole P2P DMA transfers and memory copies by the CPU by up 20%, across different levels of page cache residency. That is because it combines both page cache and P2P, dynamically choosing between them per request depending on the residence in the page cache.

In real-world applications, such as a GPU accelerated log server, SPIN achieves significant speedups over the alternative data transfer methods
