NICA: Inline Near-Data Processing on SmartNICs
NICA: Inline Near-Data Processing on SmartNICs
To accelerate networking tasks and allow customization, NIC vendors have been offering SmartNICs – programmable network interface cards – as a way to offload more CPU networking tasks to the NIC. SmartNICs, and specifically, FPGA-based SmartNICs are commonly used by cloud providers for accelerating their software defined network.
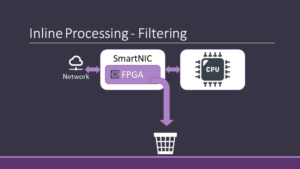
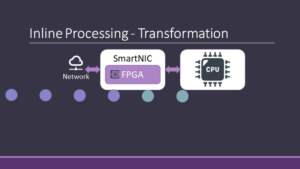
However, inline acceleration can further be used by server application to offload common networking tasks to the NIC. For example, SmartNICs can filter packets coming in from the network, reducing the CPU load and they can transform packets to formats more suitable for CPU consumption.
For example, SmartNICs can cache popular key-value pairs in a key-value store, and reduce the CPU load by responding to requests that hit the cache directly from the NIC. They can also be used to validate a cryptographic signature on incoming requests, and filter invalid requests immediately, improving performance during denial of service attacks.
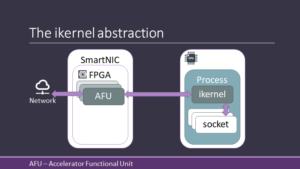 NICA provides abstractions to simplify the use of such accelerators by server applications. It uses a new abstraction – the ikernel – to instantiate and control SmartNIC AFUs (accelerator functional units). Applications may attach an ikernel to a POSIX socket, causing the socket’s traffic to be processed by the appropriate AFU on the SmartNIC.
NICA provides abstractions to simplify the use of such accelerators by server applications. It uses a new abstraction – the ikernel – to instantiate and control SmartNIC AFUs (accelerator functional units). Applications may attach an ikernel to a POSIX socket, causing the socket’s traffic to be processed by the appropriate AFU on the SmartNIC.
ikernels can be easily used in existing applications. Here is a code example:
// Create handle k = ik_create(MEMCACHED_AFU); ik_command(k, CONFIGURE, ...); // Init a socket. s = socket(...); bind(s, ...); // Activate the ikernel ik_attach(k, s); // Use POSIX APIs to receive while (recvmsg(s, buf, ...)) ...
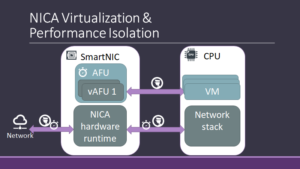
The NICA framework provides fine-grain virtualization support for AFUs, allowing a single AFU to be shared among multiple cloud tenants. This allows cloud providers to share SmartNIC resources among several tenants, improving the utilization.
By tagging the I/O interfaces of the AFU NICA is able to isolate its state, and by providing schedulers for the I/O interfaces it allows cloud providers to guarantee performance isolation for different tenants.
We implemented NICA’s hardware components and our example AFUs in C++, converting it to hardware using the Xilinx Vivado high-level-synthesis (HLS) tool. To simplify hardware development, we have developed a library of reusable packet-processing components, and a methodology for developing high-performance packet processing applications in HLS.
Our library, ntl (Networking Template Library), provides common components for data-flow processing, and allows customizing components using higher-order functions.
An example UDP parser using the functional components of ntl:
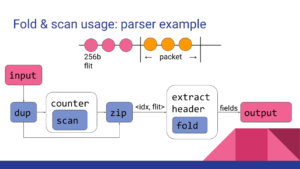
The development of ntl allows us to share code among AFUs and NICA’s infrastructure, while reaching line-rate in hardware.
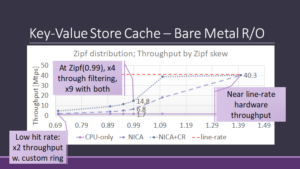
We developed a key-value store AFU cache to show the benefits of NICA, and evaluated it on a Mellanox Innova Flex card, which uses a bump-in-the-wire design.
We integrated the key-value store cache AFU with memcached and show it improves performance both in bare-metal and virtualization scenarios.