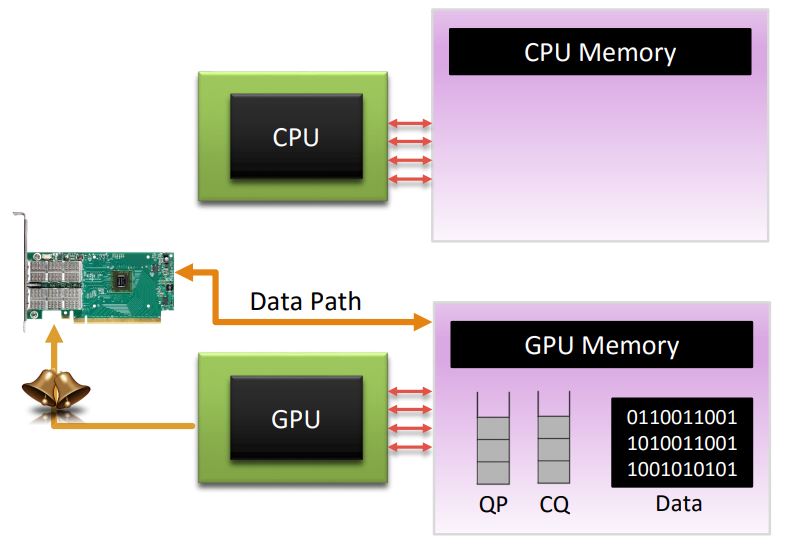
GPUrdma is a GPU-side library for performing Remote Direct Memory Accesses (RDMA) across the network directly from GPU kernels.
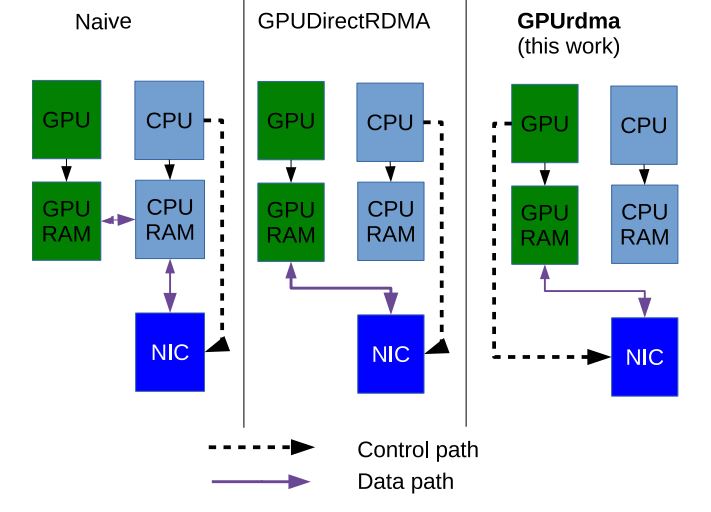
GPUrdma differs from previous works in that the CPU is completely bypassed, executing no code relevant to GPU communications. As a result, GPUrdma provides strong performance isolation of GPU communications from the CPU workloads.
GPUrdma achieves 5 usec GPU-to-GPU communication latency and up to 50 Gbps transfer bandwidth.
GPUrdma implementation
- Move QP, CQ to GPU memory. We create QP and CQ control structures and associated data buffers in GPU memory using standard CUDA memory allocation API and use peer DMA API to expose them to the Host Channel Adapter (HCA). We modify the HCA initialization routines in the original network libraries to make it possible to initialize QP/CQ with pointers to GPU memory.
- Map the HCA doorbell address into GPU address space. The HCA doorbell registers are mapped into CPU address space and can be accessed as regular memory by leveraging the memory-mapped input/output mechanism (MMIO).
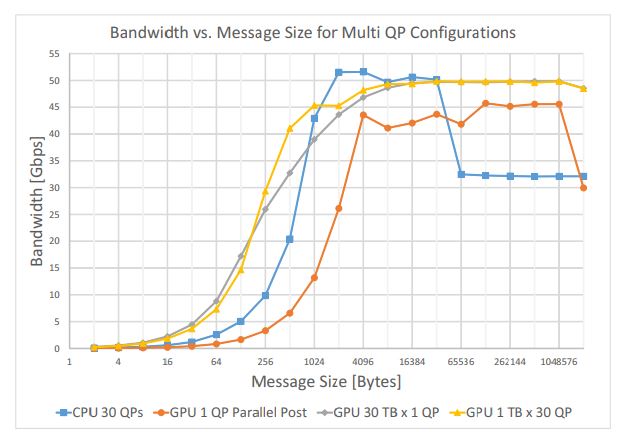
We implement the basic support for GPU-side RDMA using an NVIDIA K40c GPU with 15 streaming multiprocessors (SMs) and a Mellanox Connect-IB HCA supporting FDR (56Gbit/s). In our experiments, we invoke a GPU kernel with a single thread that issues 1024 RDMA write requests. This number of requests fits into the work queue of a single QP. We observe that the maximum bandwidth is about 43Gbit/sec, and it is achieved for very large (1 MB) messages. Smaller messages of up to 32KB achieve only 15Gbit/sec, less than one-third of the maximum network bandwidth.
Optimizations
We apply the following optimizations:
- WQE reuse. A WQE is a 64-byte structure that describes the request to the HCA, including, the request type, size, and local and remote memory addresses. Many of the fields in WQE remain the same across multiple requests. Pre-initializing all the WQEs to minimize the number of writes helps reduce latency and improve single-thread communication throughput.
- Request pipelining. The original implementation polls the completion queue after issuing each work request, waiting for each job to be received and acknowledged by the remote HCA before posting the next job. This delay is clearly unnecessary if one sends a large data stream. Therefore, a throughput-optimized version requests and waits for completion only when the QP’s work queue is full; in this way, the queue can be reused for another batch.
- Reduced writes to the doorbell. Doorbell registers reside across the PCIe bus in the HCA. Writing to these registers to signal the HCA to send the message is a costly operation that also incurs the overhead of the memory fences which precede it. Our naive implementation writes to the doorbell register for each message separately. Our optimization reduces the number of writes to the doorbell to a bare minimum, writing into it only after the QP is full.
Results
We increase the number of QPs to leverage multiple GPU threads to concurrently create multiple transfer requests. It is important to note that the use of multiple QPs is a well-known optimization for CPU transfer performance. As we show, however, this optimization has a dramatically positive effect on GPU performance. We achieve a bandwidth comparable to the QP-per-warp case, reaching 50 Gbit/sec with 16KB messages, with better scalability with respect to GPU memory consumption.