http://github.com/acsl-technion/gaia
GAIA is a weakly-consistent page cache that spans CPU and GPU memories. GAIA enables the standard mmap system call to map files into the GPU address space, thereby enabling data-dependent GPU accesses to large files and efficient write-sharing between the CPU and GPUs. Under the hood, GAIA
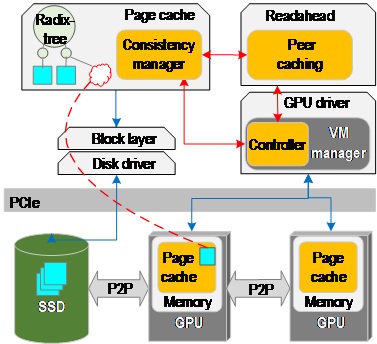 GAIA implements a distributed page cache that spans across the CPU and GPU memories. The OS page cache is extended to include a consistency manager that implements home-based lazy release consistency (LRC). It keeps track of the versions of all the file-backed memory pages and their locations. When a page is requested by the GPU or the CPU (due to a page fault), the consistency manager determines the locations of the most recent versions, and retrieves and merges them if necessary. If an up-to-date page replica is available in multiple locations, the peer-caching mechanism retrieves the page via the most efficient path, e.g., from GPU memory for the CPU I/O request, or directly from storage for the GPU access as in SPIN. This mechanism is integrated with the OS readahead prefetcher to achieve high performance. To enable proper handling of memory-mapped files on GPUs, the GAIA controller in the GPU driver keeps track of all the GPU virtual ranges in the system that are backed by files.
GAIA implements a distributed page cache that spans across the CPU and GPU memories. The OS page cache is extended to include a consistency manager that implements home-based lazy release consistency (LRC). It keeps track of the versions of all the file-backed memory pages and their locations. When a page is requested by the GPU or the CPU (due to a page fault), the consistency manager determines the locations of the most recent versions, and retrieves and merges them if necessary. If an up-to-date page replica is available in multiple locations, the peer-caching mechanism retrieves the page via the most efficient path, e.g., from GPU memory for the CPU I/O request, or directly from storage for the GPU access as in SPIN. This mechanism is integrated with the OS readahead prefetcher to achieve high performance. To enable proper handling of memory-mapped files on GPUs, the GAIA controller in the GPU driver keeps track of all the GPU virtual ranges in the system that are backed by files.
GAIA maintains the version of each filebacked 4K page for every entity that might hold the copy of the page. We call such an entity a page owner. We use the well-known version vector mechanism to allow scalable version tracking for each page. A new Time Stamp Version Table (TSVT) stores all the version vectors for a page. This table is located in the respective node of the page cache radix tree. The GPU entries are updated by the CPU-side GPU controller on behalf of the GPU. We choose the CPU-centric design to avoid intrusive modifications to GPU software and hardware.
We introduce new macquire and mrelease system calls which follow standard Release Consistency semantics and have to be used when accessing shared files.
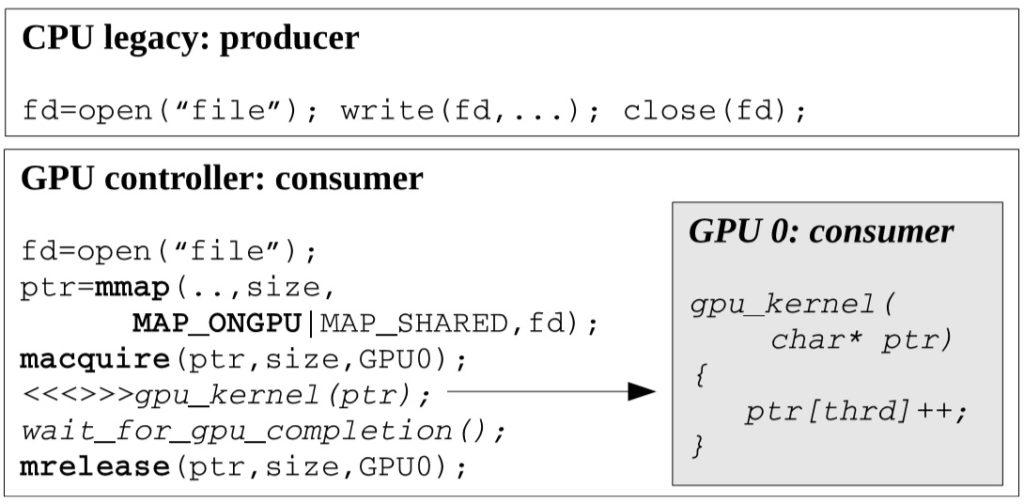
GAIA code example
Page faults from any processor are handled by the CPU. CPU and GPU-originated page faults are handled similarly. For the latter, the data is moved to the GPU. The handler locates the latest versions of the page according to its TSVT in the page cache. If the faulting processor holds the latest version in its own memory (minor page fault), the page is remapped. If, however, the present page is outdated or not available, the page is retrieved from the memory of other processors or from storage. This process involves handling the merge of multiple replicas of the same page. The overlapping writes to the same memory locations (i.e., the actual data races) are resolved via an “any write wins” policy, in a deterministic order (i.e., based on the device hardware ID). However, non-overlapping writes to the same page must be explicitly merged via 3-way merge, as in other LRC implementations.
GAIA architecture allows a page replica to be cached in multiple locations, so that the best possible I/O path (or possibly multiple I/O paths in parallel) can be chosen, to serve page access requests. In particular, the CPU I/O request can be served from GPU memory. GAIA leverages the OS prefetcher to optimize PCIe transfers. We modify the prefetcher to determine the data location in conjunction with deciding how much data to read at once. This modification results in a substantial performance boost.
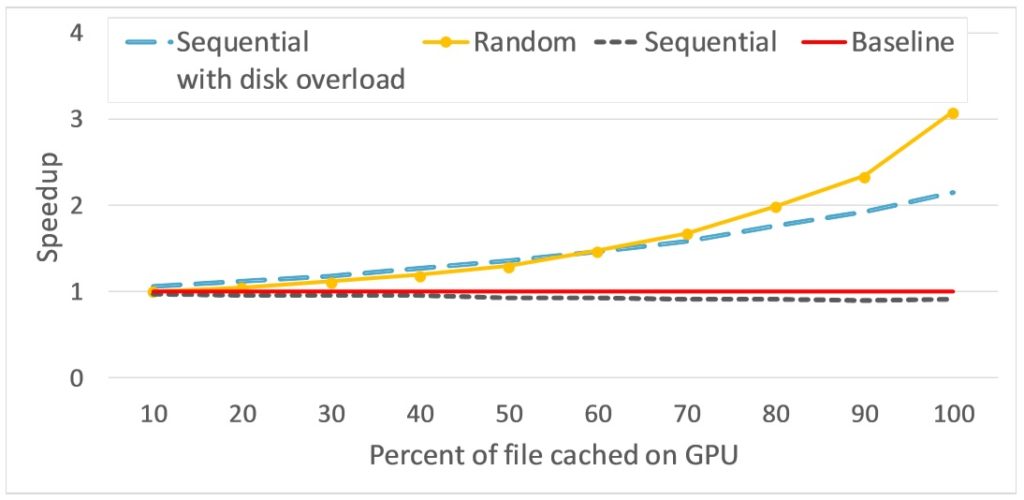
We measure the performance of CPU POSIX read accesses to a 1GB file which is partially cached in GPU memory.
GAIAs peer-caching can boost the CPU performance by up to X3 for random reads, and up to X2 when the SSD is under load.
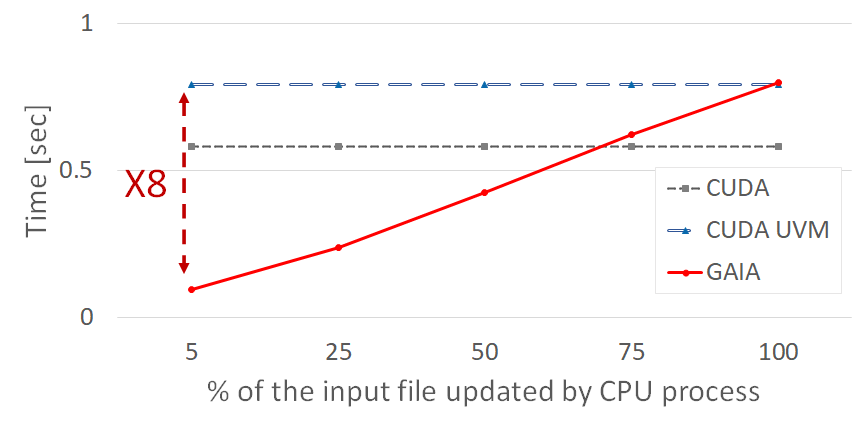
In real-world applications, such as a GPU accelerated dynamic graph processing, GAIA archives up to X8 performance improvement due to extending the page cache to GPU memory.
